Note
Go to the end to download the full example code.
4.2 Clustering
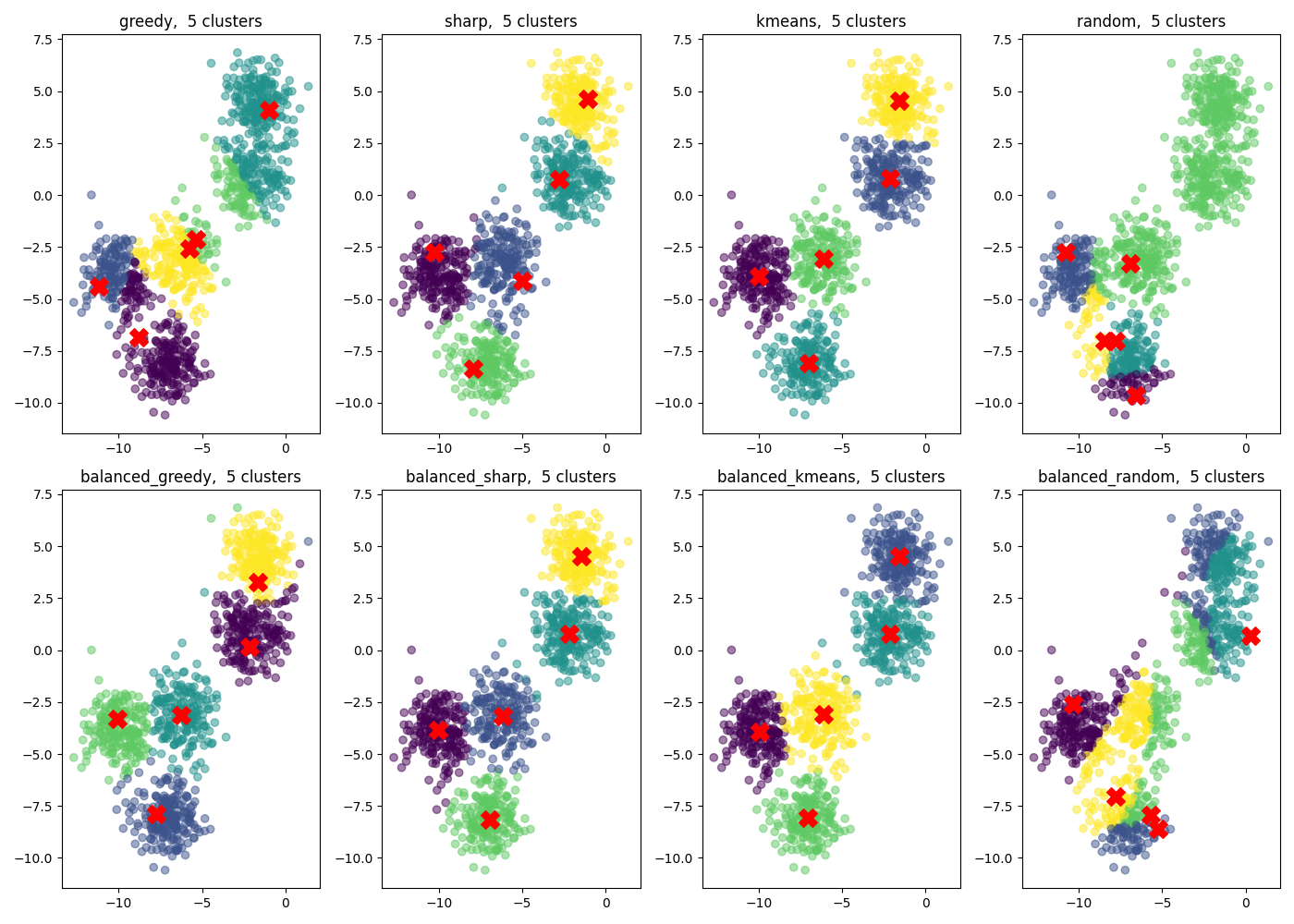
In this section, we will explore clustering methods using the CodPy library. We illustrate the behaviour of various clustering strategies, including our proposed methods, in comparison to the standard k-means algorithm. We generate a synthetic dataset in \(\mathbb{R}^2\) consisting of five well-separated Gaussian blobs (i.e., a mixture of five equally weighted Gaussian components). Each clustering algorithm is applied to partition the dataset into \(N_y\) clusters.
# Import necessary modules and setup the environment
import os
import random
import sys
import time
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import pairwise_distances
import codpy.core as core
from codpy.clustering import RandomClusters, MiniBatchkmeans, BalancedClustering, GreedySearch, SharpDiscrepancy
from codpy.kernel import Kernel
from codpy.plot_utils import multi_plot
warnings.filterwarnings("ignore")
try:
current_dir = os.path.dirname(__file__)
data_dir = os.path.join(current_dir, "data")
except NameError:
current_dir = os.getcwd()
data_dir = os.path.join(current_dir, "data")
# Ensure utils path is in sys.path
curr_f = os.path.join(os.getcwd(), "codpy-book", "utils")
sys.path.insert(0, curr_f)
Define Functions for Generating Blob Data and Clustering
def gen_blobs(Nx, Ny, D):
"""
Generate blob data for clustering.
Parameters:
- Nx: Number of samples for training.
- Nz: Number of samples for testing.
- Ny: Number of centers (clusters).
- D: Number of dimensions (features).
Returns:
- X: Generated data points.
- y: Cluster labels for each point.
"""
X, y = make_blobs(
n_samples=Nx,
n_features=int(D),
centers=int(Ny),
cluster_std=1,
center_box=(-10.0, 10.0),
shuffle=True,
random_state=1,
)
return X, y
- Clustering Models
This section defines the K-means and CodPy clustering models.
def greedy_clustering(x, Ny):
"""
Apply a fast greedy search algorithms for clustering.
Parameters:
- x: Training data.
- Ny: Number of clusters.
Returns:
- fx: Predicted cluster labels for test data.
- centers: Selected cluster centers.
"""
# Set up a kernel and select centers
kernel = GreedySearch(x=x, N=Ny, set_kernel=set_gaussian_kernel, all=True)
# retrieve the centers
centers = kernel.cluster_centers_
# retrieve labels associated to a set of points
fx = kernel.get_labels()
return fx, centers
def sharp_clustering(x, Ny):
# Set up a kernel and select centers
kernel = SharpDiscrepancy(x=x, N=Ny, set_kernel=set_gaussian_kernel)
centers = kernel.cluster_centers_
labels = kernel.get_labels()
return labels, centers
def balanced_sharp_clustering(x, Ny):
# Set up a kernel and select centers
kernel = BalancedClustering(SharpDiscrepancy, x=x, N=Ny)
centers = kernel.cluster_centers_
labels = kernel.get_labels()
return labels, centers
def kmeans_clustering(x, Ny):
kernel = KMeans(n_clusters=Ny, random_state=1).fit(x)
centers = kernel.cluster_centers_
labels = kernel.labels_
return labels, centers
def balanced_kmeans_clustering(x, Ny):
kernel = BalancedClustering(MiniBatchkmeans, x=x, N=Ny)
centers = kernel.cluster_centers_
labels = kernel.labels_
return labels, centers
def balanced_greedy_clustering(x, Ny):
method = BalancedClustering(GreedySearch, x=x, N=Ny)
centers = method.cluster_centers_
labels = method.get_labels()
return labels, centers
# class Random_clusters:
# def __init__(self, x, N, **kwargs):
# self.x = x
# self.indices = random.sample(range(self.x.shape[0]), N)
# self.cluster_centers_ = self.x[self.indices]
# def __call__(self, z, N=None, **kwargs):
# return self.distance(z, self.cluster_centers_).argmin(axis=1)
# def distance(self, x, y):
# Kernel(x=x, set_kernel=set_gaussian_kernel)
# return core.KerOp.dnm(x, y)
def balanced_random_clustering(x, Ny):
method = BalancedClustering(RandomClusters, x=x, N=Ny)
centers = method.cluster_centers_
labels = method.get_labels()
return labels, centers
def random_clustering(x, Ny):
method = RandomClusters(x=x, N=Ny)
centers = method.cluster_centers_
labels = method.get_labels()
return labels, centers
- Running the Experiment
This section runs the experiment to compare K-means and various CodPy clustering.
set_gaussian_kernel = core.kernel_setter(kernel_string="gaussian", map_string="standardmean")
def compute_mmd(x_test, z):
kernel = Kernel(x=x_test, order=0, set_kernel=set_gaussian_kernel)
mmd = kernel.discrepancy(z)
return mmd
def compute_inertia(x, y):
return np.sum((pairwise_distances(x, y) ** 2).min(axis=1))
def one_experiment(X, Ny, get_predictor):
def get_score(X, cluster_centers):
inertia = compute_inertia(X, cluster_centers)
# Calculate MMD for K-means
mmd = compute_mmd(X, cluster_centers)
return inertia, mmd
elapsed_time = time.time()
labels, cluster_centers = get_predictor(X, Ny)
elapsed_time = time.time() - elapsed_time
inertia, mmd = get_score(X, cluster_centers)
return inertia, mmd, elapsed_time
def run_experiment(Nx_values, D, Ny_values, get_predictors, labels, file_name=None):
results = []
for Nx in Nx_values:
for Ny in Ny_values:
X, _ = gen_blobs(Nx, Ny, D)
for get_predictor, label in zip(get_predictors, labels):
inertia, mmd, elapsed_time = one_experiment(X, Ny, get_predictor)
print(
"Method:",
label,
"N_partition:",
Ny,
" inertia:",
inertia,
" mmd:",
mmd,
" time:",
elapsed_time,
)
results.append(
{
"Method": label,
"Nx": Nx,
"Ny": Ny,
"Execution Time (s)": elapsed_time,
"inertia": inertia,
"mmd": mmd,
}
)
out = pd.DataFrame(results)
print(out)
if file_name is not None:
out.to_csv(file_name, index=False)
return out
def plot_experiment(Nx_values, D, Ny_values, get_predictors, names):
"""
Run the clustering experiment with different numbers of clusters (Ny) and visualize the results.
Parameters:
- Nx: Number of samples for training.
- Nz: Number of samples for testing
- D: Number of dimensions (features).
- Ny_values: List of cluster counts to experiment with.
"""
results, legends = [], []
def one_experiment(X, Ny, get_predictor):
labels, cluster_centers = get_predictor(X, Ny)
return labels, cluster_centers
for Nx in Nx_values:
for Ny in Ny_values:
X, _ = gen_blobs(Nx, Ny, D)
for get_predictor, name in zip(get_predictors, names):
labels, cluster_centers = one_experiment(X, Ny, get_predictor)
print("Method:", name, "N_partition:", Ny)
results.append((X, labels, cluster_centers))
legends.append(name + f", {Ny}" + " clusters")
# Plot the clustering results using multi_plot
def plot_clusters(data, ax, legend="", **kwargs):
x, labels, centers = data
ax.scatter(x[:, 0], x[:, 1], c=labels, cmap="viridis", alpha=0.5)
if centers is not None:
ax.scatter(
centers[:, 0],
centers[:, 1],
c="red",
marker="X",
s=200,
label="Centers",
)
ax.title.set_text(legend)
multi_plot(
results,
plot_clusters,
mp_nrows=2,
mp_ncols=len(get_predictors)//2,
mp_figsize=(14, 10),
legends=legends,
)
if __name__ == "__main__":
get_predictors = [
greedy_clustering,
sharp_clustering,
kmeans_clustering,
random_clustering,
balanced_greedy_clustering,
balanced_sharp_clustering,
balanced_kmeans_clustering,
balanced_random_clustering,
]
labels = [model.__name__.removesuffix("_clustering") for model in get_predictors]
file_name = ["clustering.csv"]
# Run the experiment
Nxs, D, Nys = [1024], 2, [5]
# core.KerInterface.set_verbose()
file_name = os.path.join(data_dir, "clustering.csv")
run_experiment(Nxs, D, [128], get_predictors, labels, file_name=file_name)
plot_experiment(Nxs, D, Nys, get_predictors, labels)
plt.show()
pass
Method: greedy N_partition: 128 inertia: 1028.1806670214105 mmd: 2.5316890621018828e-05 time: 0.03305506706237793
Method: sharp N_partition: 128 inertia: 872.1889210223746 mmd: 1.021470157003268e-05 time: 0.3940112590789795
Method: kmeans N_partition: 128 inertia: 408.9355288897727 mmd: 0.0007832229673651048 time: 0.2814466953277588
Method: random N_partition: 128 inertia: 983.0693953246964 mmd: 0.0035552788501812538 time: 0.010027170181274414
Method: balanced_greedy N_partition: 128 inertia: 615.9082479641891 mmd: 3.751833095366752e-05 time: 0.04045867919921875
Method: balanced_sharp N_partition: 128 inertia: 560.8627457110313 mmd: 1.4521889322494097e-05 time: 0.04314613342285156
Method: balanced_kmeans N_partition: 128 inertia: 425.76756358906573 mmd: 0.0005274990821971803 time: 0.27652573585510254
Method: balanced_random N_partition: 128 inertia: 1072.0714110525303 mmd: 0.0031675871040046655 time: 0.013687610626220703
Method Nx Ny Execution Time (s) inertia mmd
0 greedy 1024 128 0.033055 1028.180667 0.000025
1 sharp 1024 128 0.394011 872.188921 0.000010
2 kmeans 1024 128 0.281447 408.935529 0.000783
3 random 1024 128 0.010027 983.069395 0.003555
4 balanced_greedy 1024 128 0.040459 615.908248 0.000038
5 balanced_sharp 1024 128 0.043146 560.862746 0.000015
6 balanced_kmeans 1024 128 0.276526 425.767564 0.000527
7 balanced_random 1024 128 0.013688 1072.071411 0.003168
Method: greedy N_partition: 5
Method: sharp N_partition: 5
Method: kmeans N_partition: 5
Method: random N_partition: 5
Method: balanced_greedy N_partition: 5
Method: balanced_sharp N_partition: 5
Method: balanced_kmeans N_partition: 5
Method: balanced_random N_partition: 5
Total running time of the script: (0 minutes 2.187 seconds)