Note
Go to the end to download the full example code.
7.06 Automatic Differentiation
We reproduce here the figures 7.9, 7.10 & 7.11 of the book. Utilitary functions can be found next to this file. Here, we only define codpy-related functions.
Necessary Imports
import os
import sys
import matplotlib.pyplot as plt
import torch
try:
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
except NameError:
CURRENT_DIR = os.getcwd()
data_path = os.path.join(CURRENT_DIR, "data")
PARENT_DIR = os.path.abspath(os.path.join(CURRENT_DIR, ".."))
sys.path.insert(0, PARENT_DIR)
from utils.ch7.ch7_utils import testAAD, differentialMlBenchmarks, taylor_test, get_param21,get_param22
AAD
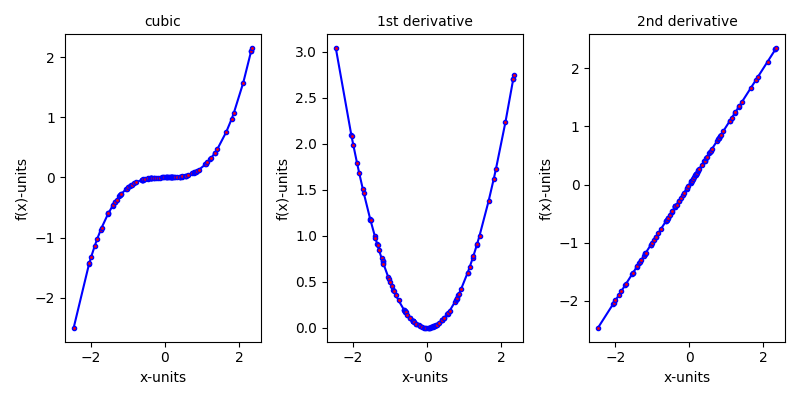
The first figure displays the computation of first- and second-order derivatives of a function \(f(X)=\frac{1}{6}X^3\) using AAD.
testAAD(lambda x: 1/6 * x**3, torch.randn((100,1), requires_grad=True))
plt.show()
1 dimensional differential machines
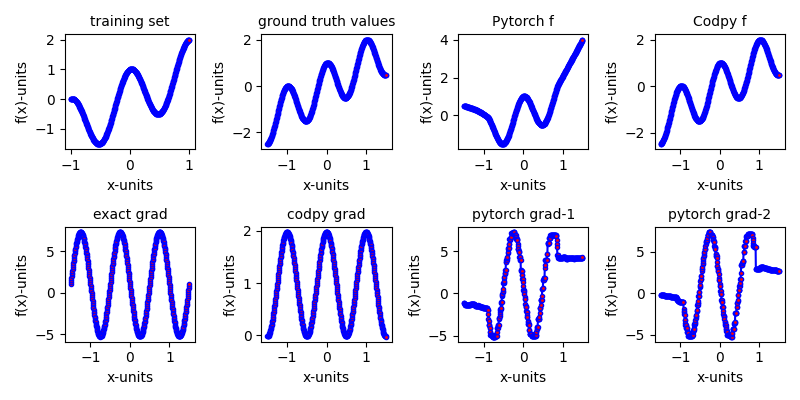
Here, we illustrate a general multi-dimensional benchmark of two differential machines methods. The first one uses the kernel gradient operator. The second one uses a neural network defined with Pytorch together with AAD tools.
differentialMlBenchmarks(D=1,N=500)
plt.show()
Sequential(
(0): Linear(in_features=1, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=128, out_features=128, bias=True)
(4): ReLU()
(5): Dropout(p=0.0, inplace=False)
(6): Linear(in_features=128, out_features=128, bias=True)
(7): ReLU()
(8): Dropout(p=0.0, inplace=False)
(9): Linear(in_features=128, out_features=128, bias=True)
(10): ReLU()
(11): Dropout(p=0.0, inplace=False)
(12): Linear(in_features=128, out_features=1, bias=True)
)
0/500 loss 0.83568
torch nabla: 1.3428218364715576
Sequential(
(0): Linear(in_features=1, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=128, out_features=128, bias=True)
(4): ReLU()
(5): Dropout(p=0.0, inplace=False)
(6): Linear(in_features=128, out_features=128, bias=True)
(7): ReLU()
(8): Dropout(p=0.0, inplace=False)
(9): Linear(in_features=128, out_features=128, bias=True)
(10): ReLU()
(11): Dropout(p=0.0, inplace=False)
(12): Linear(in_features=128, out_features=1, bias=True)
)
0/500 loss 0.84137
torch nabla: 1.2531850337982178
Sequential(
(0): Linear(in_features=1, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=128, out_features=128, bias=True)
(4): ReLU()
(5): Dropout(p=0.0, inplace=False)
(6): Linear(in_features=128, out_features=128, bias=True)
(7): ReLU()
(8): Dropout(p=0.0, inplace=False)
(9): Linear(in_features=128, out_features=128, bias=True)
(10): ReLU()
(11): Dropout(p=0.0, inplace=False)
(12): Linear(in_features=128, out_features=1, bias=True)
)
0/500 loss 0.83807
torch projection: 1.1627514362335205
codpy nabla: 0.07037615776062012
codpy projection: 0.0065724849700927734
RMSE delta codpy: 0.7808704291070304
RMSE delta pytorch: 0.47247325248239247
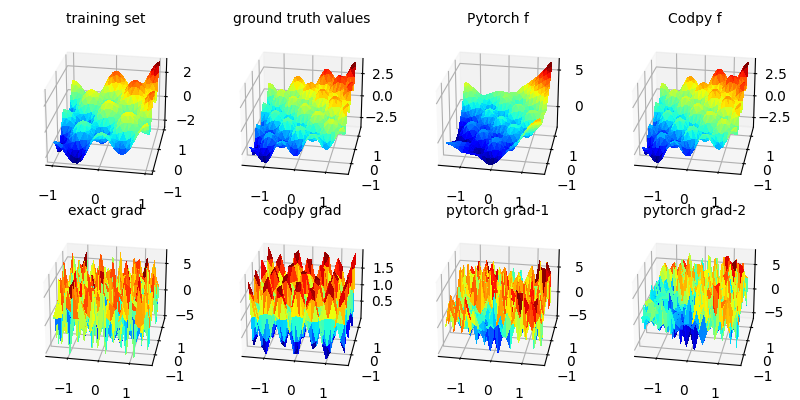
2 dimensional differential machines
We perform the same benchmark in 2 dimensions below:
differentialMlBenchmarks(D=2,N=500)
plt.show()
Sequential(
(0): Linear(in_features=2, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=128, out_features=128, bias=True)
(4): ReLU()
(5): Dropout(p=0.0, inplace=False)
(6): Linear(in_features=128, out_features=128, bias=True)
(7): ReLU()
(8): Dropout(p=0.0, inplace=False)
(9): Linear(in_features=128, out_features=128, bias=True)
(10): ReLU()
(11): Dropout(p=0.0, inplace=False)
(12): Linear(in_features=128, out_features=1, bias=True)
)
0/500 loss 1.00956
torch nabla: 1.116265058517456
Sequential(
(0): Linear(in_features=2, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=128, out_features=128, bias=True)
(4): ReLU()
(5): Dropout(p=0.0, inplace=False)
(6): Linear(in_features=128, out_features=128, bias=True)
(7): ReLU()
(8): Dropout(p=0.0, inplace=False)
(9): Linear(in_features=128, out_features=128, bias=True)
(10): ReLU()
(11): Dropout(p=0.0, inplace=False)
(12): Linear(in_features=128, out_features=1, bias=True)
)
0/500 loss 0.99518
torch nabla: 1.1354081630706787
Sequential(
(0): Linear(in_features=2, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=128, out_features=128, bias=True)
(4): ReLU()
(5): Dropout(p=0.0, inplace=False)
(6): Linear(in_features=128, out_features=128, bias=True)
(7): ReLU()
(8): Dropout(p=0.0, inplace=False)
(9): Linear(in_features=128, out_features=128, bias=True)
(10): ReLU()
(11): Dropout(p=0.0, inplace=False)
(12): Linear(in_features=128, out_features=1, bias=True)
)
0/500 loss 0.99291
torch projection: 1.1650512218475342
codpy nabla: 0.1067359447479248
codpy projection: 0.009524106979370117
RMSE delta codpy: 0.7197046151870157
RMSE delta pytorch: 0.3861852949724002
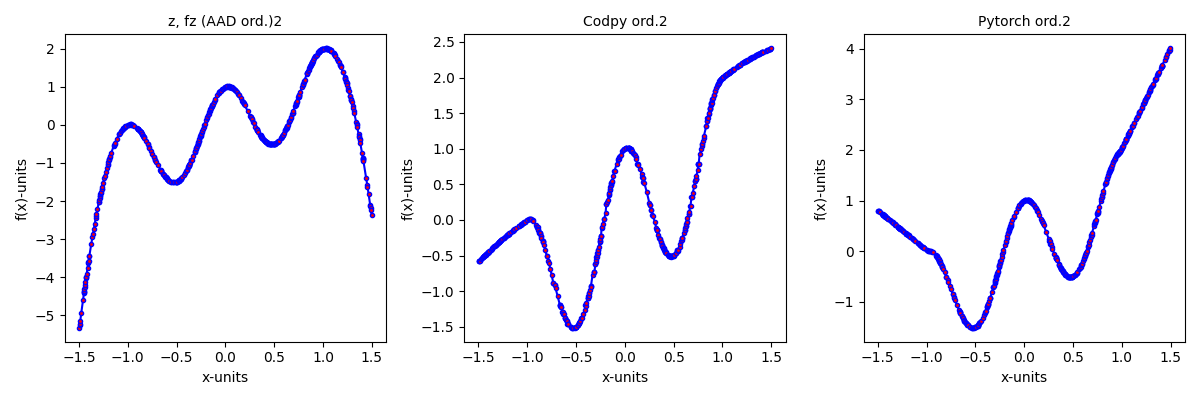
Taylor expansions and differential machines
We approximate up to second order \(\nabla f(x)\),\(\nabla^2 f(x)\) with
taylor_test(**get_param22(),taylor_order = 2)
plt.show()
Sequential(
(0): Linear(in_features=1, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=128, out_features=128, bias=True)
(4): ReLU()
(5): Dropout(p=0.0, inplace=False)
(6): Linear(in_features=128, out_features=128, bias=True)
(7): ReLU()
(8): Dropout(p=0.0, inplace=False)
(9): Linear(in_features=128, out_features=128, bias=True)
(10): ReLU()
(11): Dropout(p=0.0, inplace=False)
(12): Linear(in_features=128, out_features=1, bias=True)
)
0/500 loss 0.82311
Sequential(
(0): Linear(in_features=1, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=128, out_features=64, bias=True)
(4): ReLU()
(5): Dropout(p=0.0, inplace=False)
(6): Linear(in_features=64, out_features=1, bias=True)
)
0/500 loss 0.84781
Total running time of the script: (0 minutes 10.574 seconds)