Note
Go to the end to download the full example code.
6.2 Supervised learning: benchmarks of methods with MNIST
Here we reproduce the results of chapter 6.2.2 - Classification problem: handwritten digits. We will compare different models with codpy for a classification task, scoring models on unseen data.
- Necessary Imports
import random
import time
import matplotlib.pyplot as plt
import numpy as np
import scipy
import scipy.fft
import scipy.linalg
from scipy import ndimage
import torch
import torch.nn as nn
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LinearRegression
import torchvision.transforms.functional as tf
from torch.utils.data import DataLoader, TensorDataset
from torchvision import datasets, transforms
from typing import List,Set,Dict,get_type_hints
from PIL import Image
import codpy.core as core
import codpy.lalg as lalg
from codpy.data_processing import hot_encoder
from codpy.kernel import KernelClassifier
from codpy.plot_utils import multi_plot
from scipy.special import softmax
from codpydll import *
from codpy.kernel import Kernel,Sampler
from codpy.sampling import get_uniforms,get_normals,get_qmc_uniforms,get_qmc_normals
from codpy.permutation import lsap, map_invertion,Gromov_Monge,dic_invertion
from codpy.conditioning import ConditionerKernel
MNIST Data Preparation
We normalize pixel values and reshape data for processing. Pixel data is used as flat vectors, and labels are one-hot encoded.
def get_MNIST_data(N=-1, flatten=True, one_hot=True, seed=43):
transform = transforms.ToTensor()
train_data = datasets.MNIST(
root=".", train=True, download=True, transform=transform
)
test_data = datasets.MNIST(
root=".", train=False, download=True, transform=transform
)
x = train_data.data.numpy().astype(np.float32) / 255.0
fx = train_data.targets.numpy()
z = test_data.data.numpy().astype(np.float32) / 255.0
fz = test_data.targets.numpy()
if flatten:
x = x.reshape(len(x), -1)
z = z.reshape(len(z), -1)
if one_hot:
fx = np.eye(10)[fx]
fz = np.eye(10)[fz]
if N==-1:
N = x.shape[0]
random.seed(seed)
indices = random.sample(range(x.shape[0]), min(N,x.shape[0]))
x, fx = x[indices], fx[indices]
return x, fx, z, fz
Classification Models
Below we define the 3 classification models which will be used in our experiments. We use the accuracy loss as a metric along with Maximum Mean Discrepancy (MMD) for the codpy model to showcase the inverse relationship between the score and MMD.
# For classification tasks, use KernelClassifier.
# This is used the same way as Kernel, but it returns a softmax distribution over classes.
def RKHS_ridge_regression(x, fx, z, fz):
kernel = KernelClassifier(
x=x,
fx=fx,
clip=None, # Clipping is used for non-probability inputs
)
preds = kernel(z)
end_time = time.perf_counter()
mmd = np.sqrt(kernel.discrepancy(z))
return preds, fz, mmd, end_time
class conv_classifier(KernelClassifier):
def get_kernel(self) -> callable:
if not hasattr(self, "kernel"):
cd.set_kernel("tinv_poly_kernel",{"p": str(1)})
# ones ="1;"*(x.shape[0]-1)+"1"
# cd.set_kernel("tinv_maternnorm",{"weights" : ones})
cd.kernel_interface.set_polynomial_order(0)
cd.kernel_interface.set_regularization(1e-9)
cd.kernel_interface.set_map("scale_to_unitcube")
self.kernel = core.KerInterface.get_kernel_ptr()
return self.kernel
# pass
def cut(x,N):
out = np.array_split(x,N,axis=1)
out = [np.concatenate([np.ones([o.shape[0],1])*i,o],axis=1) for i,o in enumerate(out)]
return out
def codpy_tr_model(x, fx, z, fz,N=28):
kernels = []
xs = []
latentxs = []
kernel = None
x_splitted = cut(x,N)
fx_splitted = np.repeat(fx,len(x_splitted),axis=1)
x_splitted = [np.concatenate([x_split,fx],axis=1) for x_split,fx_split in zip(x_splitted,fx_splitted)]
count = 0
values = np.ones_like(fx)
values /= values.sum(1)[:,None]
for x_split,fx_split in zip(x_splitted,fx_splitted):
test=np.linalg.norm(x_split[1:,:N+1])
if test > 16:
x_split[:,N+1:] = values
kernel = KernelClassifier(x=x_split,fx = fx,reg=1e-9)
values = kernel(kernel.get_x())
kernels += [kernel]
count = count + 1
xs+= [kernel.get_x()]
else:
kernels += [None]
# latentxs+= [kernel(kernel.get_x())]
z_splitted = cut(z,N)
values = np.ones_like(fz)
values /= values.sum(1)[:,None]
# values = fz
for kernel,z_split in zip(kernels,z_splitted):
if kernel is not None:
z = np.concatenate([z_split,values],axis=1)
values = kernel(z)
preds = values
mmd=0
end_time = time.perf_counter()
return preds, fz, mmd, end_time
def get_weights2D(x,fx,sigma=.4):
out = np.zeros(x.shape[1])
for n in range(x.shape[1]):
j = n//28 -14
i = n%28 - 14
out[(i+28*j)%x.shape[1]]+=np.exp(-(i*i+j*j)*sigma)
# out[(i+28*j)%x.shape[1]]+=max(1-np.sqrt(i*i+j*j)*sigma,0.)
out /= out.sum()
out = scipy.linalg.toeplitz(out)
return out
def rotate(x,angle=10):
images = x.reshape(x.shape[0],28,28)
out = x.copy()
for n in range(x.shape[0]):
image = images[n]
# plt.imshow(image,cmap='gray')
image = np.asarray(tf.rotate(Image.fromarray(image),angle))
# plt.imshow(image,cmap='gray')
out[n] = image.ravel()
return out
def get_weights1D(x,fx,sigma=4.):
out = np.zeros(x.shape[1])
for n in range(x.shape[1]):
i=(n-x.shape[1]//2)
out[i%x.shape[1]]=np.exp(-i*i*sigma)
out /= out.sum()
out = scipy.linalg.toeplitz(out)
return out
def RKHS_conv_model(x, fx, z, fz,get_weights=get_weights2D):
sigma=.5
weights = get_weights(x,fx,sigma)
xcs = x@weights
xrs1=rotate(xcs,-10.)
xrs2=rotate(xcs,+10.)
xs=np.concatenate([x,xrs1,xrs2])
fxs=np.concatenate([fx,fx,fx])
classifier_kernel = KernelClassifier(x=xs,fx=fxs,clip=None)
preds = classifier_kernel(z@weights)
mmd=0
end_time = time.perf_counter()
return preds, fz, mmd, end_time
def codpy_fft_model(x, fx, z, fz,get_weights=get_weights2D):
xs=scipy.fft.fft(x,workers=-1)
# xs = np.real(xs)
xs = np.concatenate([x,np.real(xs)],axis=1)
classifier_kernel = KernelClassifier(x=xs,fx=fx,clip=None)
zs=scipy.fft.fft(z,workers=-1)
zs = np.concatenate([z,np.real(zs)],axis=1)
# zs = np.real(zs)
preds = classifier_kernel(zs)
mmd=0
end_time = time.perf_counter()
return preds, fz, mmd, end_time
def get_fun(x,fx):
left = core.KerOp.dnm(fx,fx,distance="norm22")
right = core.KerOp.dnm(x,x,distance="norm22")
J1 = (left * right).sum()
J2 = (left - right)
J2 = (J2*J2).sum()
return J1,J2
def get_J(x,fx,weights=[1,2,4,10,4,2,1]):
test = get_fun(x,fx)
out = core.KerOp.dnm(fx,fx,distance="norm22")
out = out - np.diag(out.sum(1))
out = out @ x
out = x.T @ out
out = np.identity(out.shape[0]) + out / (2.*np.max(np.fabs(out)))
return out/out.sum(1)[:,None]
def get_A(x,fx,weights=[1,2,4,10,4,2,1]):
weights=[np.exp(-n*n*.5) for n in range(-5,5)]
out = np.zeros(x.shape[1])
for n,w in enumerate(weights):
i,j = n-len(weights)//2,0
out[(i+28*j)%x.shape[1]]+=w
i,j = 0,n-len(weights)//2
out[(i+28*j)%x.shape[1]]+=w
# i,j = n-len(weights)//2,n-len(weights)//2
# out[i+28*j]+=w
# i,j = n-len(weights)//2,len(weights)//2 - n
# out[i+28*j]+=w
out = scipy.linalg.toeplitz(out)
return out/out.sum(1)[:,None]
def get_A(x,fx):
# test = get_fun(x,fx)
dfx = core.KerOp.dnm(fx,fx,distance="norm22")/(fx.shape[1]*fx.shape[1])
dx = core.KerOp.dnm(x,x,distance="norm22")/(x.shape[1]*x.shape[1])
D = dfx-dx
B = -np.ones(x.shape[0])
B = scipy.linalg.toeplitz(B)
B *= D
B -= np.diag(B.sum(1))
xs = B@x
out = x.T @ xs
U,D = lalg.LAlg.self_adjoint_eigen_decomposition(out)
D =np.array(D)
D = np.exp(-D)
out = U@np.diag(D)@U.T
test = get_fun(x@out,fx)
return out
def codpy_convolutional_model(x, fx, z, fz):
kernel = conv_classifier(
x=x,
fx=fx,
clip=None, # Clipping is used for non-probability inputs
)
preds = kernel(z)
end_time = time.perf_counter()
# mmd = np.sqrt(kernel.discrepancy(z))
mmd=0
return preds, fz, mmd, end_time
def random_forest_model(x, fx, z, fz):
# Convert inputs to numpy arrays and one-hot to labels
x = np.array(x)
fx_labels = np.argmax(np.array(fx), axis=1)
z = np.array(z)
fz_labels = np.argmax(np.array(fz), axis=1)
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(x, fx_labels)
results = model.predict(z)
num_classes = 10 # MNIST has 10 classes (0-9)
results_oh = np.zeros((len(results), num_classes))
results_oh[np.arange(len(results)), results] = 1
# Also convert true labels to one-hot for consistent return
fz_oh = np.zeros((len(fz_labels), num_classes))
fz_oh[np.arange(len(fz_labels)), fz_labels] = 1
return results_oh, fz_oh, None, time.perf_counter()
def torch_model(x, fx, z, fz):
x = torch.tensor(x, dtype=torch.float32)
fx = torch.tensor(fx, dtype=torch.long).argmax(dim=1)
z = torch.tensor(z, dtype=torch.float32)
fz = torch.tensor(fz, dtype=torch.long)
out_shape = fz.shape[1]
class FFN(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(64, output_dim),
)
def forward(self, x):
return self.net(x)
model = FFN(x.shape[1], out_shape)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
n_samples = x.shape[0]
batch_size = max(n_samples // 4, 32)
model.train()
for epoch in range(30):
indices = torch.randperm(n_samples)
for start in range(0, n_samples, batch_size):
end = min(start + batch_size, n_samples)
batch_idx = indices[start:end]
x_batch = x[batch_idx]
fx_batch = fx[batch_idx]
pred = model(x_batch)
loss = loss_fn(pred, fx_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
results = model(z)
return results.cpu(), fz.cpu(), None, time.perf_counter()
def Perceptron(x, fx, z, fz):
x = torch.tensor(x, dtype=torch.float32)
fx = torch.tensor(fx, dtype=torch.float32).argmax(dim=1)
z = torch.tensor(z, dtype=torch.float32)
fz = torch.tensor(fz, dtype=torch.float32)
out_shape = fz.shape[1]
class FFN(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 8),
nn.ReLU(),
nn.Linear(8, 32),
nn.ReLU(),
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, output_dim),
)
def forward(self, x):
return self.net(x)
model = FFN(x.shape[1], out_shape)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
n_samples = x.shape[0]
batch_size = n_samples // 4
for epoch in range(128):
# Shuffle data each epoch
indices = torch.randperm(n_samples)
for start in range(0, n_samples, batch_size):
end = min(start + batch_size, n_samples)
batch_idx = indices[start:end]
x_batch = x[batch_idx]
fx_batch = fx[batch_idx]
pred = model(x_batch)
loss = loss_fn(pred, fx_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
results = model(z)
return results, fz, None, time.perf_counter()
def vgg_torch_model(x, fx, z, fz):
x = torch.tensor(x, dtype=torch.float32).view(-1, 1, 28, 28)
fx = torch.tensor(fx, dtype=torch.float32).argmax(dim=1).long()
z = torch.tensor(z, dtype=torch.float32).view(-1, 1, 28, 28)
fz = torch.tensor(fz, dtype=torch.float32).long() # .argmax(dim=1).long()
out_shape = fz.shape[1]
dataset = TensorDataset(x, fx)
trainloader = DataLoader(dataset, batch_size=min(128, x.shape[0]), shuffle=True)
class VGG(nn.Module):
def __init__(self, input_dim=1, output_dim=10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(
in_channels=input_dim, out_channels=32, kernel_size=3, padding=1
),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Dropout2d(0.2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Dropout2d(0.3),
nn.MaxPool2d(2),
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 7 * 7, 128),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(128, output_dim),
)
def forward(self, x):
return self.classifier(self.features(x))
model = VGG(x.shape[1], out_shape)
opt = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-4)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(30):
for x_batch, fx_batch in trainloader:
pred = model(x_batch)
loss = loss_fn(pred, fx_batch)
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
results = model(z)
return results, fz, None, time.perf_counter()
Gathering Results
We train the models on different subsets of the training dataset. We always evaluate the models on the entire test set.
core.KerInterface.set_verbose()
results = {}
times = {}
mmds = {}
models = [
RKHS_conv_model,
RKHS_ridge_regression,
# torch_model,
Perceptron,
# random_forest_model,
vgg_torch_model,
]
model_aliases = {
"RKHS_conv_model": "K_CM",
"RKHS_ridge_regression": "K_RR",
# "torch_model": "FFN",
"Perceptron": "NN_PM",
# "random_forest_model": "RF",
"vgg_torch_model": "NN_VGG",
}
X, FX, Z, FZ = get_MNIST_data()
# torch.manual_seed(0)
# idxs = torch.randperm(len(X))
# idxs_z = torch.randperm(len(Z))
SIZE = 2**11
# X, FX, Z, FZ = X[idxs][:SIZE], FX[idxs][:SIZE], Z[idxs_z][:SIZE], FZ[idxs_z][:SIZE]
length_ = len(X)
scenarios_list = [
(int(i), int(i), -1, -1) for i in 2 ** np.arange(8, 12)
]
for scenario in scenarios_list:
Nx, Nfx, Nz, Nfz = scenario
x, fx, z, fz = X[:Nx], FX[:Nfx], Z[:Nz], FZ[:Nfz]
# x, fx, z, fz = X[:Nx], FX[:Nfx], X[:Nx], FX[:Nfx]
results[len(x)] = {}
times[len(x)] = {}
# mmds[len(x)] = {}
for model in models:
start_time = time.perf_counter()
logits, target, mmd, end_time = model(x, fx, z, fz)
# mmds[len(x)][model.__name__] = mmd
pred_classes = np.argmax(logits, axis=1)
true_classes = np.argmax(target, axis=1)
accuracy = accuracy_score(true_classes, pred_classes)
results[len(x)][model.__name__] = accuracy
times[len(x)][model.__name__] = end_time - start_time
print(
f"Model: {model.__name__}, size: {Nx}, Time taken: {times[len(x)][model.__name__]:.4f} seconds, Accuracy: {results[len(x)][model.__name__]:.4f} %"
)
res = [{"data": results}, {"data": times}]
# res = [{"data": results}, {"data": mmds}, {"data": times}]
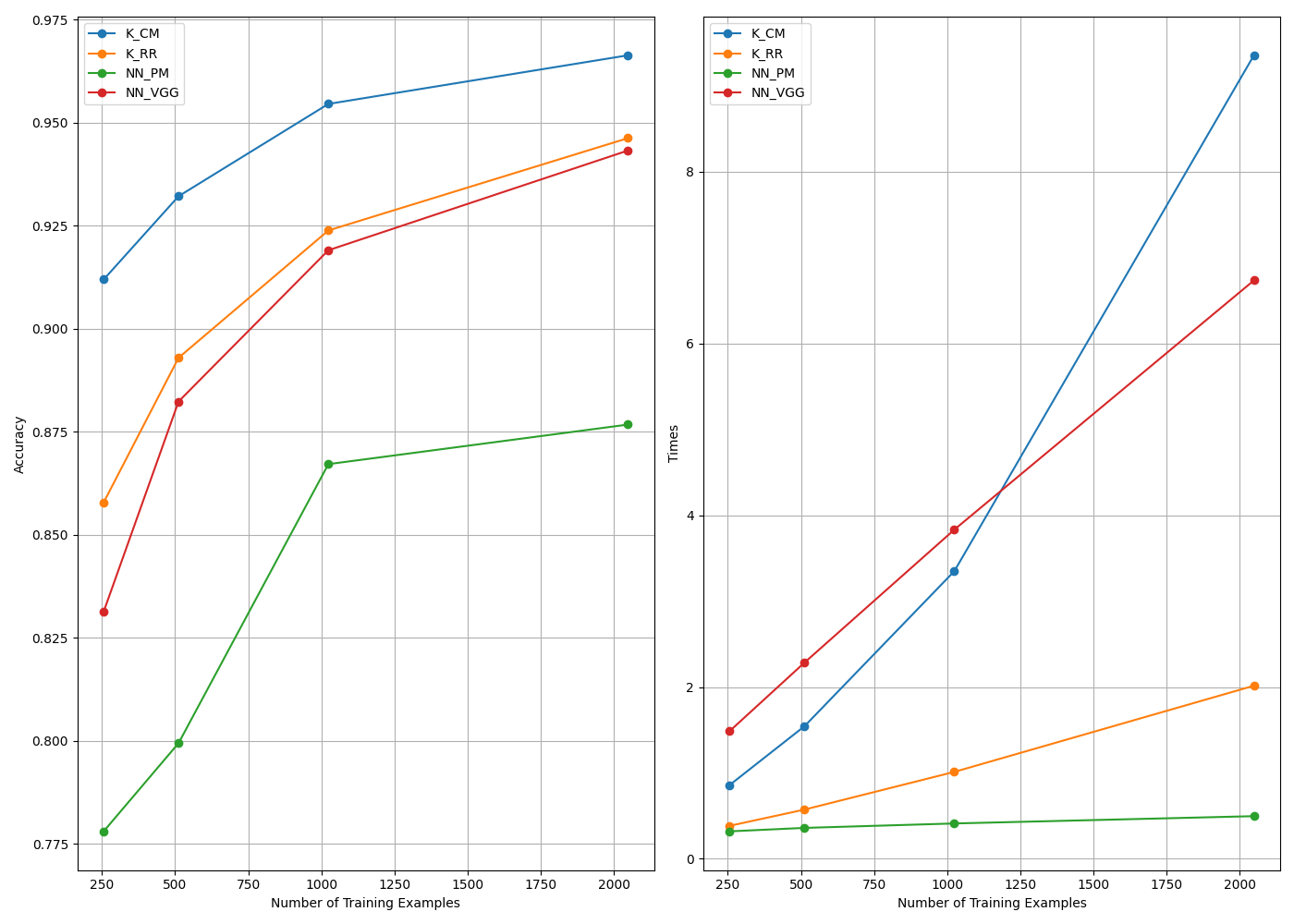
Model: RKHS_conv_model, size: 256, Time taken: 0.8587 seconds, Accuracy: 0.9119 %
Model: RKHS_ridge_regression, size: 256, Time taken: 0.3842 seconds, Accuracy: 0.8578 %
Model: Perceptron, size: 256, Time taken: 0.3200 seconds, Accuracy: 0.7780 %
Model: vgg_torch_model, size: 256, Time taken: 1.4865 seconds, Accuracy: 0.8313 %
Model: RKHS_conv_model, size: 512, Time taken: 1.5440 seconds, Accuracy: 0.9321 %
Model: RKHS_ridge_regression, size: 512, Time taken: 0.5735 seconds, Accuracy: 0.8929 %
Model: Perceptron, size: 512, Time taken: 0.3603 seconds, Accuracy: 0.7994 %
Model: vgg_torch_model, size: 512, Time taken: 2.2845 seconds, Accuracy: 0.8823 %
Model: RKHS_conv_model, size: 1024, Time taken: 3.3486 seconds, Accuracy: 0.9545 %
Model: RKHS_ridge_regression, size: 1024, Time taken: 1.0122 seconds, Accuracy: 0.9238 %
Model: Perceptron, size: 1024, Time taken: 0.4119 seconds, Accuracy: 0.8671 %
Model: vgg_torch_model, size: 1024, Time taken: 3.8322 seconds, Accuracy: 0.9190 %
Model: RKHS_conv_model, size: 2048, Time taken: 9.3553 seconds, Accuracy: 0.9663 %
Model: RKHS_ridge_regression, size: 2048, Time taken: 2.0154 seconds, Accuracy: 0.9462 %
Model: Perceptron, size: 2048, Time taken: 0.4969 seconds, Accuracy: 0.8767 %
Model: vgg_torch_model, size: 2048, Time taken: 6.7345 seconds, Accuracy: 0.9432 %
- Plotting
def plot_one(inputs):
results = inputs["data"]
ax = inputs["ax"]
legend = inputs["legend"]
x_vals = sorted(results.keys())
for model_name in next(iter(results.values())).keys():
y_vals = [results[x][model_name] for x in x_vals]
label = model_aliases.get(model_name, model_name)
ax.plot(x_vals, y_vals, marker="o", label=label)
ax.set_xlabel("Number of Training Examples")
ax.set_ylabel(legend)
ax.legend()
ax.grid(True)
return ax
multi_plot(
res,
plot_one,
mp_nrows=1,
mp_ncols=3,
legends=["Accuracy", "Times"],
mp_figsize=(14, 10),
)
plt.show()
pass
Total running time of the script: (0 minutes 50.348 seconds)