Note
Go to the end to download the full example code.
6.3 Unsupervised learning: Clustering - MNIST
We show how to reproduce the results of the chapter 6.3.2 - Application to supervised machine learning - Classification problem: handwritten digits of the book. We will compare the codpy MMD minimization-based algorithm with scikit learn k-means in an unsupervised setting. The goal is to show the different scores as we increase the number of centroids Ny used for clustering.
Necessary Imports
import os
import time
os.environ["OPENBLAS_NUM_THREADS"] = "32"
os.environ["OMP_NUM_THREADS"] = "4"
import random
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from ch6_Clustering import *
from codpy.kernel import *
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, pairwise_distances
from torchvision import datasets, transforms
try:
current_dir = os.path.dirname(__file__)
data_dir = os.path.join(current_dir, "data")
except NameError:
current_dir = os.getcwd()
data_dir = os.path.join(current_dir, "data")
curr_f = os.path.join(os.getcwd(), "codpy-book", "utils")
sys.path.insert(0, curr_f)
MNIST Data Preparation
We normalize pixel values and reshape data for processing. Pixel data is used as flat vectors, and labels are one-hot encoded.
def get_MNIST_data(N=-1, flatten=True, one_hot=True, seed=43):
transform = transforms.ToTensor()
train_data = datasets.MNIST(
root=".", train=True, download=True, transform=transform
)
test_data = datasets.MNIST(
root=".", train=False, download=True, transform=transform
)
x = train_data.data.numpy().astype(np.float32) / 255.0
fx = train_data.targets.numpy()
z = test_data.data.numpy().astype(np.float32) / 255.0
fz = test_data.targets.numpy()
if flatten:
x = x.reshape(len(x), -1)
z = z.reshape(len(z), -1)
if one_hot:
fx = np.eye(10)[fx]
fz = np.eye(10)[fz]
if N == -1:
N = x.shape[0]
indices = random.sample(range(x.shape[0]), min(N, x.shape[0]))
x, fx = x[indices], fx[indices]
return x, fx, z, fz
Clustering Models
This section defines the K-means and CodPy clustering models. We wrap the clustering methods with kernels assigning labels to clusters based on the target values fx. This allow us to compute score metrics for the models.
def codpy_sharp(x, fx, Ny):
# Select the codpy model for clustering and select centers
greedy_search = SharpDiscrepancy(x=x, N=Ny)
centers = greedy_search.cluster_centers_
# Set a classifier which will assign labels to clusters based on fx
kernel = KernelClassifier(x=x, y=centers, fx=fx)
kernel.set_kernel_ptr(greedy_search.k.kernel)
return centers, kernel
def codpy_clustering(x, fx, Ny):
# Select the codpy model for clustering and select centers
greedy_search = GreedySearch(x=x, N=Ny)
centers = greedy_search.cluster_centers_
# Set a classifier which will assign labels to clusters based on fx
kernel = KernelClassifier(x=x, y=centers, fx=fx)
kernel.set_kernel_ptr(greedy_search.k.kernel)
return centers, kernel
def kmeans_clustering(x, fx, Ny):
# Use Kmeans from sklearn to get the clusters
if Ny >= x.shape[0]:
centers = x
else:
centers = KMeans(n_clusters=Ny, random_state=1).fit(x).cluster_centers_
# Set a classifier which will assign labels to centers based on fx
kernel = KernelClassifier(x=x, y=centers, fx=fx)
return centers, kernel
Running the Experiment
This section runs the experiment to compare K-means and CodPy clustering.
def one_experiment(X, fx, Ny, get_predictor, z, fz):
def get_score(X, cluster_centers, predictor):
inertia = compute_inertia(X, cluster_centers)
mmd = compute_mmd(X, cluster_centers)
# The score is accuracy
f_z = predictor(z)
f_z = f_z.argmax(1)
ground_truth = fz.argmax(axis=-1)
out = confusion_matrix(ground_truth, f_z)
score = np.trace(out) / np.sum(out)
return inertia, mmd, score
elapsed_time = time.time()
cluster_centers, predictor = get_predictor(X, fx, Ny)
elapsed_time = time.time() - elapsed_time
inertia, mmd, score = get_score(X, cluster_centers, predictor)
return inertia, mmd, elapsed_time, score
def run_experiment(
data_generator, Nx, Ny_values, get_predictors, labels, file_name=None
):
results = []
for Ny in Ny_values:
N_MNIST_pics = Nx
x, fx, z, fz = data_generator(N_MNIST_pics)
for get_predictor, label in zip(get_predictors, labels):
inertia, mmd, elapsed_time, score = one_experiment(
x, fx, Ny, get_predictor, z, fz
)
print(
"Method:",
label,
"N_partition:",
Ny,
"inertia:",
inertia,
"mmd:",
mmd,
"time:",
elapsed_time,
"score",
score,
)
results.append(
{
"Method": label,
"Nx": Nx,
"Ny": Ny,
"Execution Time (s)": elapsed_time,
"inertia": inertia,
"mmd": mmd,
"score": score,
}
)
out = pd.DataFrame(results)
print(out)
if file_name is not None:
out.to_csv(file_name, index=False)
return results
Plotting
This section formats data plots the different experiments on a figure.
def plot_experiment(inputs):
"""
This is mainly boilerplate formatting the data for plotting.
"""
results = [{"data": {}} for _ in range(4)]
for res in inputs:
ny = res["Ny"]
method = res["Method"]
t = res["Execution Time (s)"]
inertia = res["inertia"]
mmd = res["mmd"]
score = res["score"]
results[0]["data"].setdefault(ny, {})[method] = score
results[1]["data"].setdefault(ny, {})[method] = mmd
results[2]["data"].setdefault(ny, {})[method] = inertia
results[3]["data"].setdefault(ny, {})[method] = t
def plot_one(inputs):
results = inputs["data"]
ax = inputs["ax"]
legend = inputs["legend"]
for model_name in next(iter(results.values())).keys():
x_vals = sorted(results.keys())
y_vals = [results[x][model_name] for x in x_vals]
ax.plot(x_vals, y_vals, marker="o", label=model_name)
ax.set_xlabel("Ny")
ax.set_ylabel(legend)
ax.legend()
ax.grid(True)
return ax
multi_plot(
results,
plot_one,
mp_nrows=1,
mp_ncols=4,
mp_figsize=(14, 10),
legends=["Scores", "discrepancy_errors", "inertia", "execution_time"],
)
get_predictors = [
lambda X, fx, N: codpy_sharp(X, fx, N),
lambda X, fx, N: codpy_clustering(X, fx, N),
lambda X, fx, N: kmeans_clustering(X, fx, N),
]
labels = ["sharp", "greedy", "kmeans"]
file_name = ["clustering.csv"]
Nxs, Nys = 2**14, [10, 20, 40, 80, 160]
file_name = os.path.join(data_dir, "clusteringMNIST.csv")
results = run_experiment(
get_MNIST_data, Nxs, Nys, get_predictors, labels, file_name=file_name
)
plot_experiment(results)
plt.show()
pass
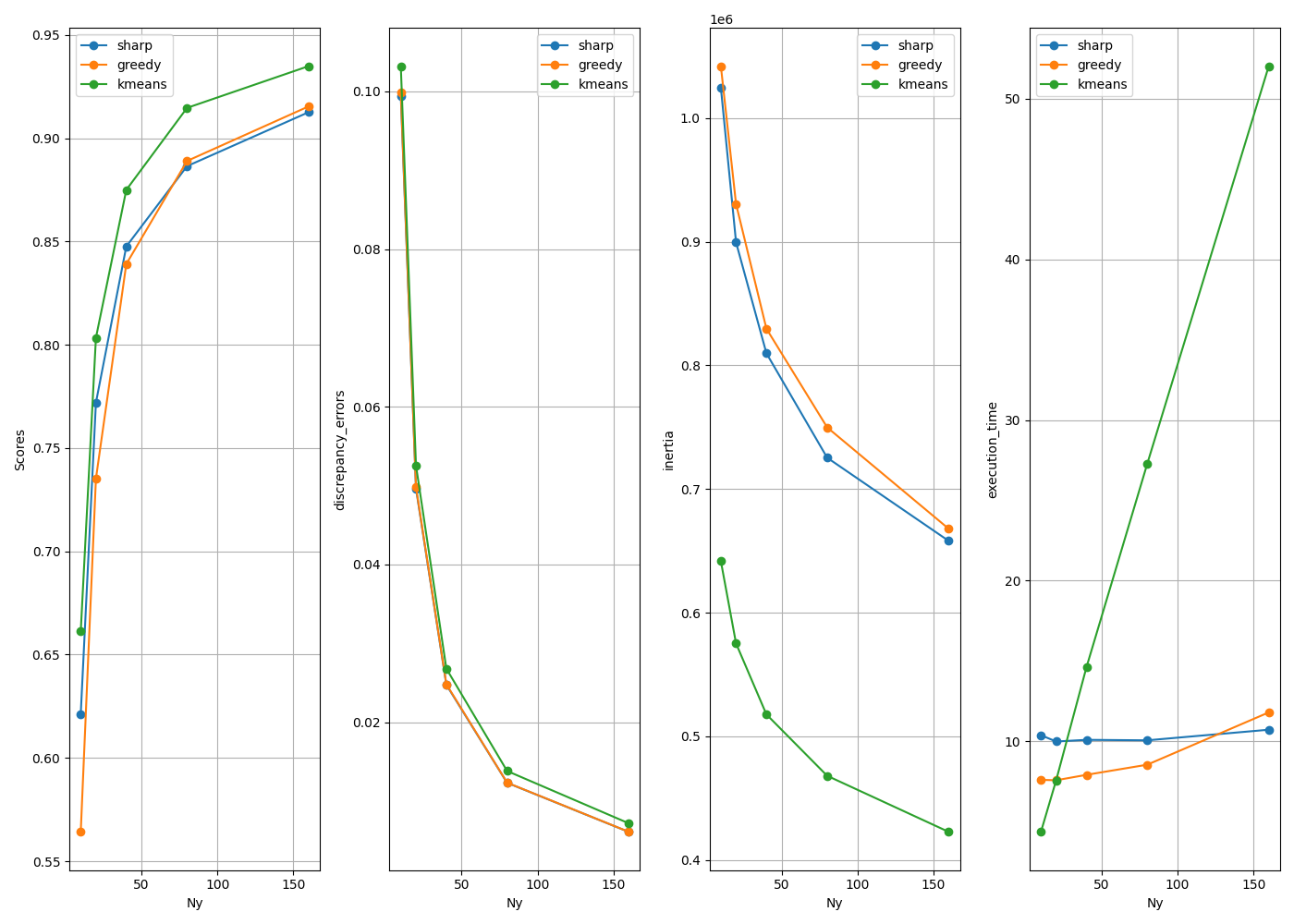
Method: sharp N_partition: 10 inertia: 1024720.1955304628 mmd: 0.09943460384506246 time: 10.381416320800781 score 0.6213
Method: greedy N_partition: 10 inertia: 1042107.44 mmd: 0.09984419518406468 time: 7.601225852966309 score 0.5642
Method: kmeans N_partition: 10 inertia: 641655.5 mmd: 0.1031823923502955 time: 4.36320161819458 score 0.6612
Method: sharp N_partition: 20 inertia: 899549.5336495735 mmd: 0.04964997447279737 time: 9.987433910369873 score 0.772
Method: greedy N_partition: 20 inertia: 930546.8 mmd: 0.049803074194573145 time: 7.574997901916504 score 0.7352
Method: kmeans N_partition: 20 inertia: 575083.25 mmd: 0.05256263460208673 time: 7.565404891967773 score 0.8034
Method: sharp N_partition: 40 inertia: 809813.6708939021 mmd: 0.02475697909007022 time: 10.091619729995728 score 0.8476
Method: greedy N_partition: 40 inertia: 829706.2 mmd: 0.024824193298942473 time: 7.913812637329102 score 0.8391
Method: kmeans N_partition: 40 inertia: 517675.06 mmd: 0.02680274944038916 time: 14.617313385009766 score 0.875
Method: sharp N_partition: 80 inertia: 725346.1801268021 mmd: 0.012330486562238419 time: 10.061444520950317 score 0.8865
Method: greedy N_partition: 80 inertia: 749866.2 mmd: 0.012347328151657514 time: 8.543874502182007 score 0.889
Method: kmeans N_partition: 80 inertia: 468029.28 mmd: 0.013829700367252635 time: 27.270869255065918 score 0.9147
Method: sharp N_partition: 160 inertia: 658056.7769389395 mmd: 0.006112326355559444 time: 10.721572637557983 score 0.9126
Method: greedy N_partition: 160 inertia: 667876.25 mmd: 0.006124400149152115 time: 11.799237489700317 score 0.9154
Method: kmeans N_partition: 160 inertia: 422664.94 mmd: 0.007203589722670812 time: 52.02327632904053 score 0.9349
Method Nx Ny Execution Time (s) inertia mmd score
0 sharp 16384 10 10.381416 1.024720e+06 0.099435 0.6213
1 greedy 16384 10 7.601226 1.042107e+06 0.099844 0.5642
2 kmeans 16384 10 4.363202 6.416555e+05 0.103182 0.6612
3 sharp 16384 20 9.987434 8.995495e+05 0.049650 0.7720
4 greedy 16384 20 7.574998 9.305468e+05 0.049803 0.7352
5 kmeans 16384 20 7.565405 5.750832e+05 0.052563 0.8034
6 sharp 16384 40 10.091620 8.098137e+05 0.024757 0.8476
7 greedy 16384 40 7.913813 8.297062e+05 0.024824 0.8391
8 kmeans 16384 40 14.617313 5.176751e+05 0.026803 0.8750
9 sharp 16384 80 10.061445 7.253462e+05 0.012330 0.8865
10 greedy 16384 80 8.543875 7.498662e+05 0.012347 0.8890
11 kmeans 16384 80 27.270869 4.680293e+05 0.013830 0.9147
12 sharp 16384 160 10.721573 6.580568e+05 0.006112 0.9126
13 greedy 16384 160 11.799237 6.678762e+05 0.006124 0.9154
14 kmeans 16384 160 52.023276 4.226649e+05 0.007204 0.9349
Total running time of the script: (5 minutes 25.077 seconds)